- Все статьи цикла:
- Дизайн данных (часть 1). Что и зачем?
- Дизайн данных (часть 2). Как?
- Дизайн данных (часть 3). Меняемся?
- Дизайн данных (часть 4). Матчасть: основы.
- Дизайн данных (часть 5). Матчасть: базы данных.
- Дизайн данных (часть 6). Матчасть: API.
- Дизайн данных (часть 7). Прототипирование. (вы здесь)
Это завершающий пост цикла про data design. Самый хардкорный и — самый полезный. Разумеется, до него добрались лишь немногие. Слабые и юные отсеялись на предыдущих статьях, остались лишь закалённые суровым проектированием передачи и хранения данных.
Если же вы по какой-то невероятной причине решились сходу нырнуть в прототипирование, не испытав свой характер шестью предыдущими статьями — я искренне вам сочувствую. И рекомендую, всё же, начать с лайтового, плавного погружения в тему.
А мы пока продолжим.
1. Проблема
Никто не проектирует большие сервисы заранее и целиком. Это нерационально, вредно для сердца и кошельков инвесторов. Но всегда есть базовый этап проектирования, который нужно закончить, прежде чем первая строчка кода опасливо выползет из IDE программиста в командный git-репозиторий.
Уровень продуктового дизайнера определяет, в числе прочего, и то, насколько глубоким будет этот самый базовый этап. Кому-то хватит лишь концепции продукта и первой пары вайрфреймов, а кто-то упорется по продумыванию гибкой и масштабируемой архитектуры. И только совсем матёрые попробуют с самого начала заложить основу для стабильной работы продуктовой команды. Так вот ниже я расскажу, как стабилизировать и ускорить разработку за счёт технического прототипирования.
1.1. Первый этап позади
Представим, что вот вы добрались до финальной стадии первого этапа проектирования. Опрошены толпы респондентов, собрана тонны инфы о рынке и ЦА. Команда разработки уже считает вас своей роднёй — столько времени вы провели с ними, выпытывая тонкости будущей реализации (а если команды пока нет — такой же роднёй считает вас гугл). Всё это время вы не забывали про дизайн данных, и информационная архитектура будущего сервиса стала прекраснее рассвета в швейцарских горах.

Жизнь восхитительна, несмотря на поседевшие за время проектирования виски. И, вроде бы, можно начинать… но какая-то мелкая заноза не даёт вам «спустить курок» разработки. Что это? Перфекционизм или паранойя?
Скорее всего, это смутное осознание того, что ни один проект не разрабатывается строго по документации. Даже NASA, с их жёсткими, как Борис Бритва, стандартами — и те вносят изменения в продукт по ходу его реализации. А это значит, что часть вашей работы, ваш пот и кровь, будут тупо слиты в канализацию нестабильной разработки и поздних исследований. И ничего с этим не поделаешь. Вроде бы.
На самом деле, ещё как поделаешь. Идеального проектирования не бывает, и документация не высечена в камне, чтобы быть неизменной. Однако мы в состоянии минимизировать эти изменения — или, хотя бы, сделать их появление разумным и ожидаемым.
Давайте рассмотрим одну из фундаментальных причин того, почему в 90% случаев разработка ведётся, мягко говоря, не оптимально.
1.2. Мягко говоря
Какой бы методологии не придерживалась ваша проектная команда, почти всегда есть один фактор, снижающий динамику разработки. Он же заставляет программистов скакать из контекста в контекст, переключаясь между задачами, делая их работу менее эффективной.
Этот фактор звучит просто: «клиент ждёт сервер». Этой проблеме столько лет, что она уже стала частью проектной практики — и самые крутые продакты и тимлиды заранее закладывают в бюджет небольшой простой разработчиков.
Как это выглядит. Серверный программист написал фичу, клиентский (например, мобильный) — заюзал эту фичу в приложении. Пока приложение на стороне клиента не может получить информацию по API, фича не может быть до конца разработана и протестирована. Для наглядности вот вам картинка:

Красные области — это время, которое клиентские разработчики ждут, пока метод API заработает на сервере. В самом начале такой области нет, потому что на старте проекта мобильным или веб-разработчикам ещё не до API, они пишут основную архитектуру. Зато потом…
Простаивающие разработчики — это деньги, выброшенные впустую. Это даже хуже, чем классический пример с водкой и пивом — потому что там у вас остаётся хотя бы один ингредиент. В случае с разработчиками же у вас не остаётся ничего. Компания платит им зарплату за то, что они не работают. И даже если на свой стартап вы набрали фрилансеров, получающих почасовую оплату, это всё равно обернётся для вас дополнительными расходами. Хотя бы потому, что фрилансер, почуяв простой (а значит, отсутствие денег) возьмёт еще одну подработку — а значит, по возвращению у него будет период переключения контекста. Его работа будет менее эффективна.
То же самое справедливо и для случаев, когда в компании тимлид пытается закрыть простои дополнительными задачами. Типа «о, сервер будет готов только через два дня; давай-ка ты пока пофиксишь вон тот баг с низким приоритетом». Контекст меняется, эффективность падает. Меняются планы, сползает роадмап, теряются деньги. В какой-то момент команда отказывается от реализации нескольких мелких фич, потому что внезапно начинает подкрадываться овербаджет.
Продукт получается хуже и дороже, чем мог бы быть.
2. Решение
А теперь представьте, что API готов с самого начала. Может, не полностью, но в той мере, которая нужна клиентским разработчикам, чтобы никого не ждать, а просто пилить свой чёртов код.
Что, если вы, крутой дизайнер данных, с самого-самого начала предоставите им рабочий прототип API? Там будут фейковые данные, не будет сложной логики — но это будут методы, которые отдают реальный формат ответов.
2.1. Серверная разработка
Имея на старте такой прототип, серверный программист просто «транслирует» ваш API через реальный сервер. Получается, что с самого старта все методы готовы, но отдают «прототипированную» информацию. Назовём такие методы «заглушками». По мере работы, наш программист просто заменяет «заглушки» на реальные методы, возвращающие уже самые что ни на есть реальные данные.
Сервер изначально знает все форматы ответов. Ничего не нужно выдумывать, стараться унифицировать, бояться что-то пропустить. Разработка без страха. Мечта прям.
2.2. Клиентская разработка
Просто пишет код. Да, мобильные или веб-разработчики оглядываются на то, что изначально данные приходят фейковые. Возможно (если ваш прототип простенький), обработку некоторых ошибок на первых порах придётся делать, руководствуясь исключительно документацией. Тестировщикам порой придется прогонять тест-кейсы дважды — но в этом нет ничего плохого.
Клиентские программисты никого не ждут. Теперь они не вынуждены постоянно синхронизироваться с динамикой серверной разработки. Они решают задачи в порядке приоритетов, а не основываясь на собственной занятости.
2.3. Визуально
Если совсем упростить, то получается примерно вот такая схемка:

Конечно, не всегда клиент обгоняет сервер по скорости запила фич в продакшн. Однако такая схема позволяет вообще переосмыслить последовательность разработки каждого компонента — сервер, например, может сначала сделать то, что удобно с точки зрения архитектуры, не оглядываясь на потребности клиентской части. Серверный и клиентский кодинг теперь практически независимы друг от друга.
2.4. Да ну нафик
Но это всё в теории, скажите вы. На практике, чтобы зафигачить такой прототип, нужно уметь кодить. Да ещё иметь собственный сервер, чтобы разместить там этот код. Да и вообще, это занимает тьму тьмущую времени — не факт, что оплата работы дизайнера не превысит потенциальную выгоду от пресловутой стабилизации разработки.
И это было бы так, если бы человечество постоянно не развивалось — и в какой-то момент его представители не подарили бы миру целый ворох потрясающих сервисов и инструментов для быстрого прототипирования всего и вся, включая API. Несколько ниже мы пройдёмся по некоторым из них, а пока давайте-ка вернёмся к нашему прекрасному приложению про миграцию тюленей — пора переходить к более практической части.
3. Прототипирование API
Любое прототипирование начинается с документации. Тем более, прототипирование техническое. А значит, нам сперва нужно описать запросы и ответы будущего API.
В предыдущей статье про дизайн данных мы с вами очень подробно разобрали все сущности нашего сервиса, их свойства и даже типы данных, а в третьей статье проходились по конкретным запросам. Если вы знакомились с ними давно — возможно, стоит освежить в памяти логику их формирования, ибо сейчас мы уже начнём составлять реальные методы API.
И ещё момент. Если вы еще не знакомы с синтаксисом JSON, крайне рекомендую это сделать — все запросы и ответы будут формироваться именно в этом формате. Он не сложный.
А при возникновении сомнений в правильности написанного вами json-запроса/ответа, всегда можно воспользоваться одним из валидаторов JSON.
3.1. Запросы и ответы
Итак, поехали. Для каждого метода я кратко напоминаю его суть — и сразу даю текст/код запросов ответов. Не переходите к следующему, пока не разобрались в текущем.
3.1.1. Регистрация и аутентификация
Здесь на сервер мы отправляем номер телефона, а обратно получаем статус и глобальный идентификатор. Ну и, разумеется, помним про заголовки (userSecretKey и userGuid оставляем пустыми) .
Название запроса
registration
Запрос
Headers
userSecretKey:
userGuid:
appVersion: 1.0.1
appDeviceId: 2fc4b5912826ad1
appPlatform: iOS
Body
{
"dt_request": "registration",
"phone": 79667778899
}Положительный ответ
Body
{
"dt_status": "success",
"userGuid": "c0deaca4-db8a-4178-8863-eaf2494833b9"
}3.1.2. Подтверждение номера телефона
Здесь на сервер отправляется код из СМС, глобальный идентификатор пользователя и идентификатор устройства, а обратно улетает статус и секретный ключ.
Название запроса
confirm
Запрос
Headers
userSecretKey:
userGuid: c0deaca4-db8a-4178-8863-eaf2494833b9
appVersion: 1.0.1
appDeviceId: 2fc4b5912826ad1
appPlatform: iOS
Body
{
"dt_request": "confirm",
"code": 4509
}Положительный ответ
Body
{
"dt_status": "success",
"userSecretKey": "4af0744c305991c098753117a6a19690"
}3.1.3. Получение списка точек
В заголовках запроса мы указываем глобальный идентификатор пользователя, идентификатор устройства и секретный ключ, а в параметрах — отступ и область видимости. В ответ же получаем статус и массив (список) точек.
Название запроса
getPoints
Запрос
Headers
userSecretKey: 4af0744c305991c098753117a6a19690
userGuid: c0deaca4-db8a-4178-8863-eaf2494833b9
appVersion: 1.0.1
appDeviceId: 2fc4b5912826ad1
appPlatform: iOS
Body
{
"dt_request": "getPoints",
"offset": 0,
"scope": 60
}Положительный ответ
Body
{
"dt_status": "success",
"points": [
{
"dateTime": "2019-09-12T19:05:12-03",
"coords": {
"long":"59.5194488",
"lat":"150.4879161"
},
"thumb": {
"url":"/thumbs/uat12ia.jpg",
"hash":"05991c09f0744a4c38756903117a6a19"
},
"picture": {
"url":"/picture/hrdt6q7.jpg",
"hash":"305991c094af0744c876a1969053117a"
}
},
{
"dateTime": "2019-09-13T19:075:13-12",
"coords": {
"long":"59.5110862",
"lat":"150.7186927"
},
"thumb": {
"url":"/thumbs/uiwy66q.jpg",
"hash":"04c876a305991c1969053471194af07a"
},
"picture": {
"url":"/picture/wad5h7a1.jpg",
"hash":"9a455991a6c387690310c017a19f0744"
}
}
]
}3.1.4. Ошибки
Конечно, не забываем про ошибки. Это крайне важно, потому что унификация обработки ошибок существенно упрощает разработку и (главное) поддержку и развитие проекта.
Ошибки могут быть универсальными и не-универсальными. Первые сервер может вернуть в ответ на различные запросы, тогда как вторые всегда принадлежат конкретному методу. В нашем случае, например, ошибка валидации номера телефона может возникнуть только в тот момент, когда мобильное приложение отправляет на сервер запрос о регистрации пользователя — потому что больше нигде номер телефона не используется. Это не-универсальная ошибка. Универсальной же, к примеру, можно считать ошибку «пользователь не найден».
В идеале, при создании документации не-универсальные ошибки нужно описывать в конкретном методе, а универсальные можно вынести в отдельный раздел (или просто указать, что это универсальная ошибка). Разумеется, при описании тех запросов, которые потенциально могут вернуть универсальные ошибки, нужно об этом прямо заявить. Но так как мы не создаём реальные доки, все ошибки мы засунем в единый раздел — так вам будет проще.
Итак, ошибки. У каждой будет статус, код и текст.
Пользователь не найден
Возвращается в случае, если пользователя с указанными userGuid нет в БД. Универсальная ошибка.
Body
{
"dt_status": "error",
"dt_errorCode": [110],
"dt_errorMessage": "User is not found"
}Не пройдена авторизация
Возвращается в случае, если передан некорректный userSecretKey. Универсальная ошибка.
Body
{
"dt_status": "error",
"dt_errorCode": [120],
"dt_errorMessage": "Authorisation Error"
}Некорректный номер телефона
Возвращается в случае, если номер телефона не соответствует нужному формату. Может возникнуть только при выполнении метода registration.
Body
{
"dt_status": "error",
"dt_errorCode": [210],
"dt_errorMessage": "Wrong phone number"
}Неверный код из СМС
Возвращается в случае, если передан некорректный код из СМС. Может возникнуть только при выполнении метода confirm.
Body
{
"dt_status": "error",
"dt_errorCode": [220],
"dt_errorMessage": "Invalid SMS code"
}Переданы неверные параметры
Возвращается в случае, если переданы некорректные параметры запроса (например, в запросе getPoints значение scope не кратно значению offset). Универсальная ошибка.
Body
{
"dt_status": "error",
"dt_errorCode": [310],
"dt_errorMessage": "Invalid parameters passed"
}Разумеется, это не весь список. Обязательно нужно предусмотреть совсем пограничные ситуации, вроде «неизвестной ошибки сервера» (когда мы по какой-то причине не можем сообщить на клиент, в чём именно проблема). Есть ещё ситуации, когда запрос улетел, а сервер не ответил, потому что упал (или пропала связь).
У меня в проектах словарь ошибок, как правило, насчитывает от 40 до 70 различных кодов. При этом все они разделены на группы: например, ошибки, связанные с пользователем, имеют коды 1XX, а ошибки, связанные конкретно с регистрацией/аутентификацией/авторизацией (вроде «некорректного кода из СМС») — коды 2XX. И так далее.
3.2. Инструменты
Чуть ранее я обещал рассказать вам про инструментарий прототипирования API. На самом деле, таких инструментов — лютая тьма, но я их субъективно делю на три условных группы:
- базовые инструменты;
- сервисы;
- фреймворки.
3.2.1. Базовые инструменты
Как правило, обладают довольно узким набором возможностей. Например, умеют преобразовывать разметку Markdown в конкретный код. Или умеют валидировать HTTP-запросы.
Пример такого инструмента — API Blueprint. Это довольно крутой высокоуровневый язык описания API в уже упомянутом Markdown. Есть ещё Dredd, который может автоматически тестировать API (хотя он, скорее, фреймворк, просто очень узкоспециализированный).
Прототипируя API, использовать такие инструменты по отдельности довольно сложно — придётся их связывать между собой.
3.2.2. Сервисы
Вот это — вариант большинства дизайнеров данных. В состав таких сервисов уже входят связки различных базовых инструментов. Прототипирование в них не требует каких-то особенных знаний, кроме языка разметки и понимания того, что ты делаешь. Платить за простоту приходится какими-то ограничениями: например, нельзя настроить логику обработки запросов или тип запроса всегда указывается в URL (а не отдельным параметром, как у нас в приложении про тюленей). Но с этим можно жить.
Хорошие примеры таких сервисов — Apiary и Swagger. Обратите внимание на первый, к нему мы ещё вернёмся.

Ещё рекомендую посмотреть на целую программу для быстрого прототипирования — Materia Designer (устарело, в настоящее время не поддерживается — прим.). Она умеет не только API, но и базы данных, и даже сервер. Там всё очень визуально и нужно уметь проектировать БД, но бонусом идёт практически настоящий серверный код. Я лично знаю несколько маленьких проектов, которые крутятся именно на ней.
3.2.3. Фреймворки
А вот это уже для тех, кто в своей жизни познал некоторое количество кодинга. По сути, это набор готовых решений на каком-либо языке программирования. Работа с ними занимает несколько больше времени, чем с сервисами (плюс надо хотя бы немного знать язык), но и возможностей у них побольше.
Примеров приводить не стану, так как выбор здесь всегда очень и очень индивидуален для каждого проекта/дизайнера.
3.3. Реальный прототип
Чтобы не быть голословным, я действительно собрал в Apiary простенький, но рабочий прототип API нашего несуществующего приложения. Да, там методы указаны в URL (а не параметром). Да, нет серверной логики (всегда возвращаются положительные ответы, вне зависимости от заголовков и параметров). Но этого достаточно, чтобы реализовать базовую функциональность мобильного приложения. А ошибки обрабатывать согласно документации. Полюбуйтесь, в общем.
Более того, на моём полудохлом гитхабе даже есть разметка этого прототипа. Вы можете самостоятельно завести новый проект в Apiary, скопипастить в него текст по ссылке и поэкспериментировать (осторожно, возможно отравление Markdown’ом).
На этом с прототипированием API мы закончили. Если у вас остались вопросы (а странно, если это не так), велкам в комментарии.
4. На десерт — прототипирование БД
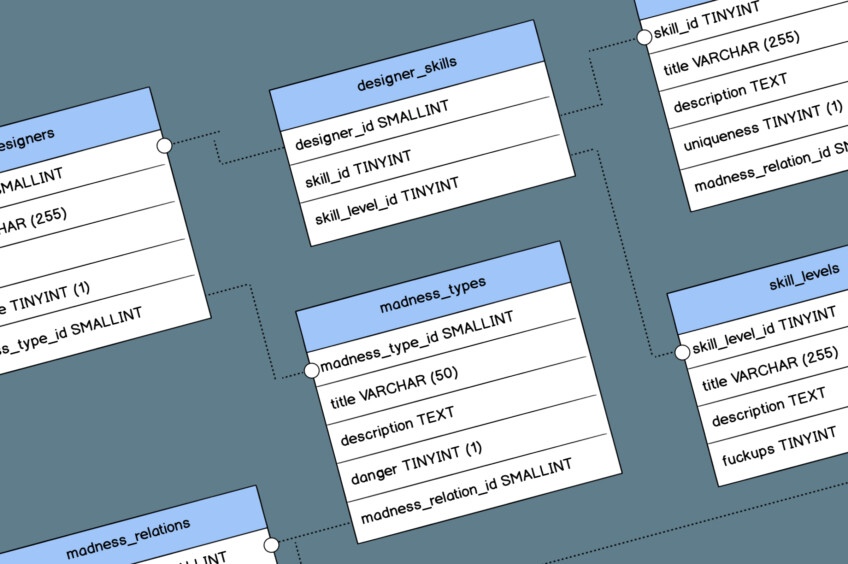
Я специально оставил эту часть напоследок, как менее важную. По статистике, до этой части полутехнического лонгрида доживают считанные единицы. И всё же, я не могу не коснуться темы прототипирования базы данных — просто потому, что реальные профи data design должны уметь хотя бы читать ER-диаграммы. А в идеале — создавать базовую структуру БД уже на старте проекта.
4.1. Зачем делать прототип базы данных?
Причина, на самом деле, довольно простая, и я о ней уже говорил. Стабилизация. Плюс — упрощение развития и поддержки проекта, оптимизация скорости работы продукта.
В большинстве случаев база данных создаётся серверным программистом в одиночку. Очень и очень редко у вас будет под рукой выделенный архитектор, способный запихнуть в свою гениальную голову весь проект — и в итоге выдать структуру базы. Чаще всего БД создаётся поэтапно, по мере того, как разработчик доходит в реализации до какого-то нового участка. Требовать от него какого-то идеала сложно — как правило, они очень функциональные люди, и мыслят соответственно. Выйти на уровень абстракции всего проекта они, конечно, могут — но сделать это правильно способны только сеньоры или очень и очень крепкие мидлы.
Чем больше проект, тем чаще в нём остаются какие-то рудименты в виде неиспользуемых свойств сущностей, странных и порой очень запутанных связей, неверных типов данных и так далее. Индексировать такую базу сложно, возрастает нагрузка на сервер. В итоге БД работает медленнее, чем могла бы. Её куда сложнее поддерживать и практически невозможно отрефакторить.
4.2. Что нужно сделать?
Самый простой способ — поговорить с серверным разработчиком и дать ему полный список сущностей и свойств проекта. Желательно также отдельно указать на их взаимосвязи (конечно, разработчик должен быть знаком с проектом хотя бы на уровне концепции). Нормально, если он после этого сможет дать какие-то рекомендации и дизайнер доработает свою документацию.
Это был минимум. Максимум — нужно научиться выбирать вид базы данных, формировать её структуру и составлять правильную визуализацию. Если же делать эту самую визуализацию в правильном инструменте, то можно сразу выгнать дамп структуры базы — он-то и станет основой прототипа БД.
4.3. Инструменты
Выбор правильного инструмента во многом зависит от вида БД, и даже иногда от конкретной СУБД. Но так как чаще всего весь мир мобильной и веб-разработки использует реляционные БД, то рассматривать мы будем именно их.
И тут у нас довольно большой выбор. Есть онлайн-сервисы, вроде Vertabelo, есть десктопные приложения, вроде MySQL Workbench или уже упоминаемой Materia. Онлайн удобен, когда над БД работают несколько человек, а десктопные программы хороши, когда нужно собрать сложную SQL-логику или в оффлайне.

Если вас заинтересовала тема, можете пощупать эти софтины или поискать другие — благо, гуглятся они довольно легко.
5. Риски прототипирования API и БД
Как обычно, есть и ложка дёгтя. Она небольшая, но в нашем случае бочку с мёдом испортит безвозвратно. Если коротко, то она звучит как «хреново спроектировал». И это не шутка. Если отнестись к прототипированию халатно, то вместо оптимизации разработки вы получите обратную ситуацию, дестабилизацию.
На самом деле, такое прототипирование здорово расслабляет программистов. Они рассчитывают на вас, ваши доки и прототипы. И если в обычной ситуации им бы пришлось нести за всё ответственность самим (что, по понятным причинам, повышает внимательность к архитектурным деталям), то в этом случае они могут и не заметить какого-то недостатка, пока не станет слишком поздно.
Ниже я собрал наиболее вероятные ошибки прототипирования БД и API.
5.1. Унификация
Не унифицировали имена параметров, сущностей, методов и тп (либо не прописали правила такого именования) — в результате при развитии API и БД получили целый зоопарк разных названий, не связанных единой семантикой. Погружение новых участников в проект стало происходить медленнее, а старым участникам стало требоваться больше времени, чтобы разобрать собственный код месячной давности.
5.2. Не полная картина проекта
В силу своей лени или неопытности, забыли про несколько методов API. Когда мобильная разработка дошла до этой части проекта, сервер был занят совершенно другой работой. В итоге вернулись к смене контекста, ухудшению производительности. Дизайнер понёс репутационные потери.
5.3. Обработка ошибок
По какой-то причине не были задокументированы (в случае простого прототипа) или реализованы (в случае прототипа сложного) некоторые ошибки API. Программисты справедливо рассудили, что «нет в доках — не делаем». Приложение стало крашиться или вести себя непредсказуемо. На отладку и обратный инжиниринг стало уходить много времени.
5.4. Связи, сущности и свойства
Забыли про связи между некоторыми сущностями (или упустили их свойства), из-за чего была неверно создана база данных. Так как существующая часть БД оказалась уже задействована, пришлось вводить дополнительные таблицы. Усложнилось развитие и масштабирование продукта.
5.5. Коммуникации
Не создали у рабочей группы единого понимания задач и смысла прототипов. Программисты стали воспринимать их как часть документации, а не инструмент для оптимизации работы. Вред небольшой, но работа дизайнера данных полетела псу под хвост.
6. Заканчиваем
Вот, собственно, и всё. Цикл постов про дизайн данных завершён. Вероятнее всего, я ещё буду что-то добавлять в блог по мере появления идей, но этих семи статей уже должно хватить для старта и базового погружения в область. Помните, что продуктовый дизайн — это не только про картинки, это про продукт целиком.
И спасибо, что дочитали до конца.
- Все статьи цикла:
- Дизайн данных (часть 1). Что и зачем?
- Дизайн данных (часть 2). Как?
- Дизайн данных (часть 3). Меняемся?
- Дизайн данных (часть 4). Матчасть: основы.
- Дизайн данных (часть 5). Матчасть: базы данных.
- Дизайн данных (часть 6). Матчасть: API.
- Дизайн данных (часть 7). Прототипирование. (вы здесь)


