- Все статьи цикла:
- Дизайн данных (часть 1). Что и зачем?
- Дизайн данных (часть 2). Как?
- Дизайн данных (часть 3). Меняемся?
- Дизайн данных (часть 4). Матчасть: основы.
- Дизайн данных (часть 5). Матчасть: базы данных. (вы здесь)
- Дизайн данных (часть 6). Матчасть: API.
- Дизайн данных (часть 7). Прототипирование.
Те, кто читает мой цикл про дизайн данных регулярно, уже наверняка приметил, что каждую статью я начинаю с того, что советую сперва ознакомиться с первыми частями. Делаю я это по понятным причинам: если сразу залезть в дебри, можно очень быстро растерять мотивацию, ибо нифига не понятно.
В прошлый раз мы говорили про самый базис матчасти: хранение, передачу информации, типы данных. Так вот эта статья будет посвящена именно хранению информации в БД, а следующая — передаче данных по API.
Мы не будем упарываться и съедать мозг сложными техническими историями — чаще всего продуктовому дизайнеру достаточно лишь верхнеуровневого понимания работы и различий между базами данных.
1. Зачем это дизайнеру
Затем же, зачем и остальной data design. Понимая, каким образом данные могут храниться и соотноситься между собой, грамотный продуктовый дизайнер может выстроить определенную модель отношений между сущностями в проекте. Стабилизация дальнейшей разработки стоит того, чтобы в самом начале потратить немного времени на выбор, например, подходящего типа БД.
При этом я вовсе не призываю всех дизайнеров бросать фигму и мчаться проектировать базы данных. Чаще всего, этим должен заниматься более технически подкованный человек (архитектор или даже специальный «дизайнер баз данных» — такой тоже есть). Однако понимание основ такого проектирования позволит существенно упростить работу этого самого архитектора. А заодно сделать более качественно проработанный продукт.
2. Немного вводных
Для начала — давайте вкратце пройдёмся по терминологии.
2.1. СУБД
Как я уже рассказывал в предыдущей статье, для управления базами данных требуется определённый софт. Без него БД — это просто файлы. Которые, к тому же, нельзя открыть обычными программами, вроде блокнота (чаще всего). Этот софт, необходимый для манипуляций с базами данных, называется СУБД — Системы Управления Базами Данных. Они позволяют создавать базы, структурировать, изменять/удалять/добавлять данные, защищать их и так далее.
2.2. Связи
Данные в БД должны быть связаны друг с другом. В основном, используются три вида таких связей (их ещё называют «кардинальность»):
- связь «один к одному»;
- связь «один ко многим»;
- связь «многие ко многим».
В чем их различие, понятно из названия. Но я всё равно немного расскажу об этом.
2.2.1. Один к одному (1:1)
Этот тип связи встречается довольно редко.
При связи «один к одному» объект из одной части БД может быть связаны только с одним объектом из другой части. Сложно, поэтому покажу на примере.
Классический пример связи «один к одному» — это серия и номер паспорта. Здесь каждый номер привязан к серии и наоборот. Серия паспорта без номера бессмысленна, равно как и номер без серии.

Иногда оказывается, что связь 1:1 — это просто ошибка проектирования. В нашем примере куда правильнее было бы сделать элемент «паспорт» со свойствами «серия» и «номер». А вот, например, связь «человек» и «паспорт» — хороший пример адекватного решения «один ко одному».
Где применяется:
- Когда данные логически разделены, но принадлежат одной сущности.
- Когда часть данных вынесена в отдельную таблицу по соображениям безопасности или производительности.
Как реализуется в БД:
- Через внешний ключ, который является уникальным в обеих таблицах.
- Иногда — просто объединением таблиц, если нет причин их разделять.
2.2.2. Один ко многим (1:N)
В этом случае один объект может быть связан с одним или несколькими объектами в другой части БД. Но эти «вторые» объекты могут связаны только с одним «первым» объектом. Давайте снова на примере.
Есть база данных торгового предприятия. В базе есть клиенты и их заказы. Так вот у одного клиента может быть несколько заказов, тогда как заказ всегда относится только к одному клиенту.

Где применяется:
- Самый частый тип связи в реальных моделях.
- Используется, когда есть чёткая «главная» и «зависимая» сущность.
Как реализуется в БД:
- В таблице «многих» хранится внешний ключ на «одного».
- Например: в таблице
ordresесть колонкаclient_id, ссылающаяся на таблицуclients.
2.2.3. Многие ко многим (M:N)
Этот тип связи походит, когда связи могут «перекрещиваться» — когда один объект может иметь отношение к нескольким объектам из другой части БД, но и эти «вторые» объекты могут относиться к нескольким «первым» объектам.
Хороший пример — кино и актёры. В одном фильме могут сниматься несколько актёров (множественная связь «фильм-актёр»), но и у одного актёра может быть несколько фильмов, в которых он снимался (множественная связь «актёр-фильм»).

Такой тип связи очень популярен в реляционных БД, о которых мы поговорим ниже.
Где применяется:
- Когда обе стороны равноправны и могут иметь множество связей друг с другом.
Как реализуется в БД:
- Через промежуточную таблицу, которая хранит пары связей.
- Например: таблица
actors_filmsс полямиactor_idиfilm_id.
3. Виды баз данных
Все БД можно очень чётко разделить на виды — в зависимости от модели данных, которую они используют.
3.1. Иерархическая БД
В иерархической БД данные хранятся, как папки на компьютере: всегда есть родительские элементы, а есть дочерние. Этот вид является самым «древним» — первые БД были преимущественно именно иерархическими. В современном мире они применяются редко, разве что для очень специфических задач.

Здесь нельзя выстроить связи между данными типа «многие ко многим» — а это очень часто требуется в проектировании. Отчасти поэтому иерархический вид БД не особенно популярен.

Иерархические БД следует использовать только в том случае, когда данные в вашем проекте всегда подчиняются строгой иерархии, а неожиданных связей между ними не возникнет даже при развитии системы.
Пример СУБД для иерархической базы данных — IMS от IBM.
3.2. Сетевая БД
Сетевая база данных — это те же иерархическая, но на стероидах. В ней можно устанавливать какие угодно связи: дочерний объект может обращаться к «предку предка» напрямую, минуя лишние шаги.
Здесь (обычно) тоже нельзя использовать связи типа «многие ко многим», но это компенсируется скоростью работы с большим количеством связанных данных.

Сетевые БД стоит использовать, если в вашем проекте большое количество связей между объектами, и эти связи реально сложны и запутаны.
Отдельного упоминания заслуживают так называемые «графовые» БД — разновидность сетевых. Не буду на них останавливаться, если интересно, загуглите сами.
Пример сетевой графовой СУБД, распространяемой по свободной лицензии — OrientDB.
3.3. Реляционная БД
Самый распространённый вид баз данных. Особенность реляционных БД в чёткой и понятной структуре информации, представленной в виде двумерных таблиц. В каждой такой таблице есть строки (собственно, объекты данных) и столбцы (свойства этих объектов). При этом столбцы, как правило, подчиняются очень чёткой типизации: конкретный столбец может содержать только один тип данных — например, строку или число. При этом одинаковых строк (элементов) в таблице не может быть.
На рисунке ниже «столбцы» представлены «строками» не только для удобства восприятия, но и потому что именно так обычно визуализируются реляционные БД (об этом я расскажу чуть ниже).

Вот так выглядит реляционная база данных в редакторе. По сути, каждая такая БД — это просто список тех самых двумерных таблиц:

А вот пример структуры отдельной таблицы. Слова «meta_id», «post_id», «meta_key» и «meta_value» — это те самые «столбцы», которые несут в себе свойства элементов:

И вот, наконец, уже сами данные этой самой таблицы. Здесь строки — это элементы (объекты данных), а у столбцов «meta_id», «post_id», «meta_key» и «meta_value» есть конкретные значения — свойства этих элементов:

Если данные в вашем проекте структурированы, по ним нужен быстрый поиск, то ваш выбор однозначно должен пасть на реляционную БД. Да и вообще, если сомневаетесь — используйте именно этот вид.
Сейчас самая популярная реляционная СУБД — MySQL от Oracle.
3.4. Остальные виды
На самом деле, существует еще довольно много других видов БД: объектно- или документо-ориентированные, функциональные и разные смеси, вроде объекто-реляционных баз. Но это, чаще всего, диковинки, заточенные под выполнение конкретных, довольно специфических задач. Но если тема вас зацепила, можете погуглить.
4. Визуализация
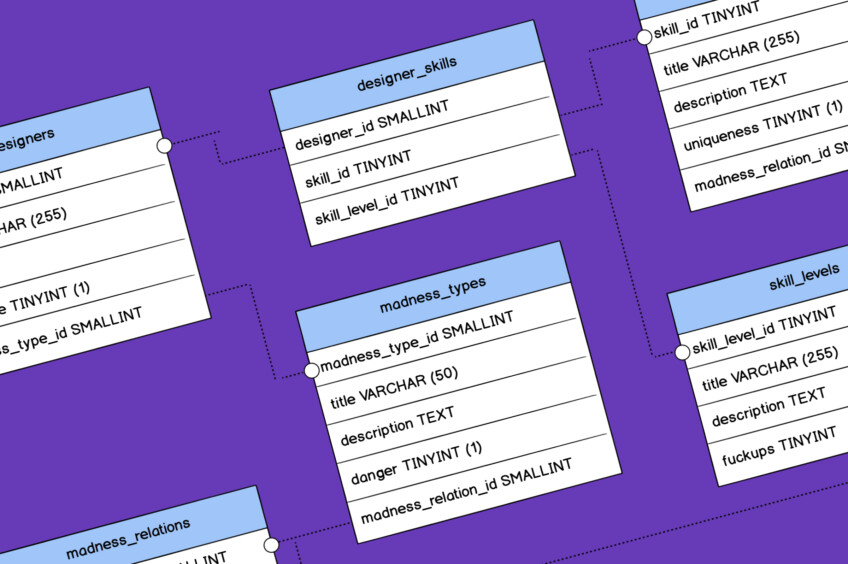
Результатом проектирования БД должен стать какой-то графический или текстовый объект — здесь всё понятно. Обычно это схема или несколько таблиц, связанных между собой. Человечество придумало огромное количество способов передать структуру данных, но наибольшее распространение получила так называемая ER-модель (её ещё называют ER-диаграммой).
По сути, это и есть диаграмма, в которой указаны все элементы, свойства и связи между ними. Стилизованную ER-диаграмму вы можете увидеть на всех миниатюрах к этому циклу статей. Вот она без лишней графики:

А вот — настоящая ER-диаграмма (к слову, отнюдь не самая большая):

Наверное, стоило бы рассказать про ER-модель поподробнее, но мне, признаться, лень создавать еще один материал на эту тему. Нотация описана уже миллион раз и без проблем гуглится.
5. В заключение
Конечно, это только начало. Я многое не рассказал, и не собираюсь — просторы интернета ломятся от серьезных, вдумчивых статей про базы данных. Но подступаться к ним с нулевого уровня знаний всегда очень сложно. Теперь же вы хотя бы немного погружены в контекст. Хотя бы понимаете, куда копать — если захотите, конечно.
- Все статьи цикла:
- Дизайн данных (часть 1). Что и зачем?
- Дизайн данных (часть 2). Как?
- Дизайн данных (часть 3). Меняемся?
- Дизайн данных (часть 4). Матчасть: основы.
- Дизайн данных (часть 5). Матчасть: базы данных. (вы здесь)
- Дизайн данных (часть 6). Матчасть: API.
- Дизайн данных (часть 7). Прототипирование.